AIの進化により音楽生成までがAIで可能になりつつあります。DNA配列が人間の設計図であるかのように、音楽生成も設計図となる音楽トークン配列というものから生成されていきます。このトークン配列は「音楽のDNA」のようなもので、それを元にして、ピアノもギターもドラムも、あのすばらしい音楽が再現できてしまうのです。ここではMusicLMやSunoなどの音楽生成AIがどういう仕組みで音楽を生成しているのかをおおまかに説明します。
全体構成
まず、全体構成ですが、音楽生成AIは、大きく3つの部分で成り立っています。
- VQ-VAE (音をトークン化する)
- Transformer (音楽の設計図を作る)
- Diffusion (ノイズから設計図に基づいた音を生成する)
全体のブロック図としてはこのようになります。
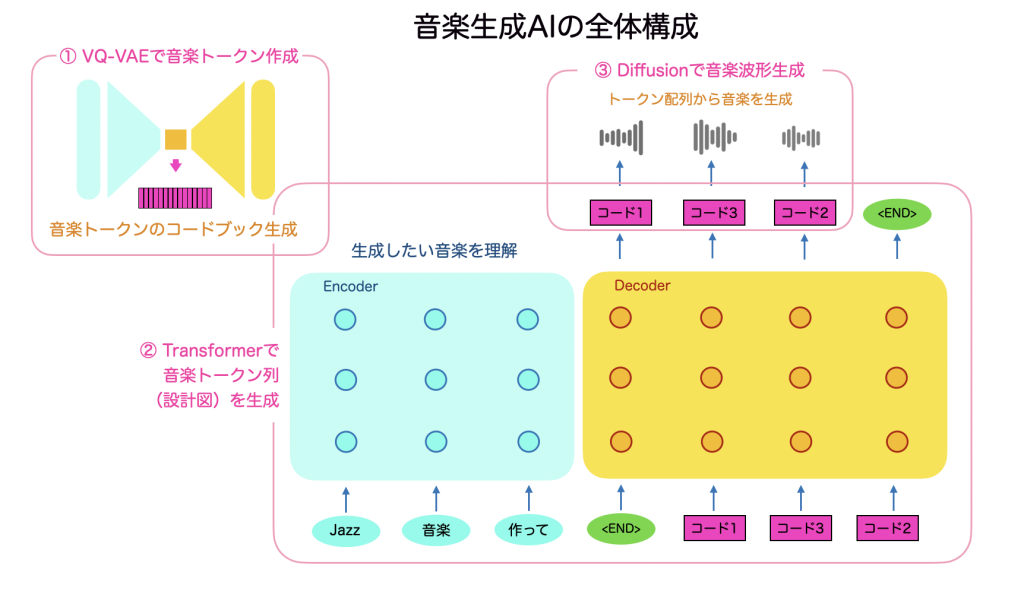
まず①のVQ-VAEで音楽トークンをコードブックとして定義していきます。だいたい512種類ぐらいのコードを定義し、これらが音楽トークンとなります。この音楽トークンの配列が音楽の設計図となります。
次に②のTransformerで言語的な指示をもとに、音楽トークン配列が生成されます。この配列ですでにリズムやテンポ、曲調などの音楽の概念的な情報がすでに出来上がっています。
最後に③のDiffusionモデルで、音楽トークン配列から音楽波形を生成していきます。ひとつの音楽トークンからは20ms程度の波形が生成されますが、もちろん配列の前後を見て音楽として繋がるように生成していきます。
こうして出来上がった音楽は、すでに人が作る音楽と同じぐらいのクオリティになっております。
それではそれぞれのステップについて解説していきます。
VQ-VAE (Vector Quantized – Variational Auto Encoder)
まずは音楽のトークン化でこれにはオートエンコーダというニューラルネットワークが用いられます。オートエンコーダとは何かですが、もともとは入力したデータと同じデータが出力できるニューラルネットワークを作ることが目的であります。それ自体には意味がないのですが、その中間層を小さくすることによって、入力データをより少ない情報で表現できる(次元圧縮ができる)ということになります。
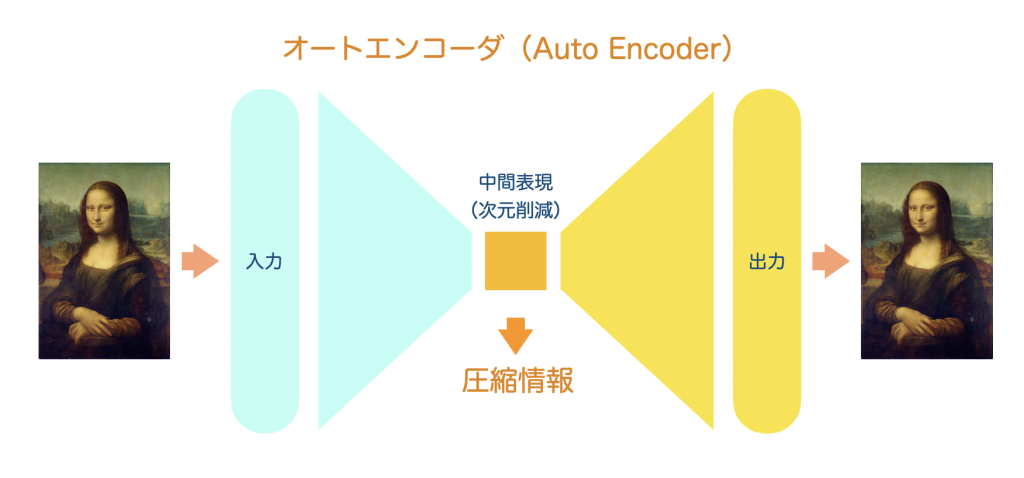
このオートエンコーダの派生系としてさまざまなものがあります。たとえばノイズ混じりの入力データから綺麗なデータを出力させるDAE(Denoising Auto Encoder)は、元データにノイズを付加したものを入力させてノイズを取り除く学習をさせます。
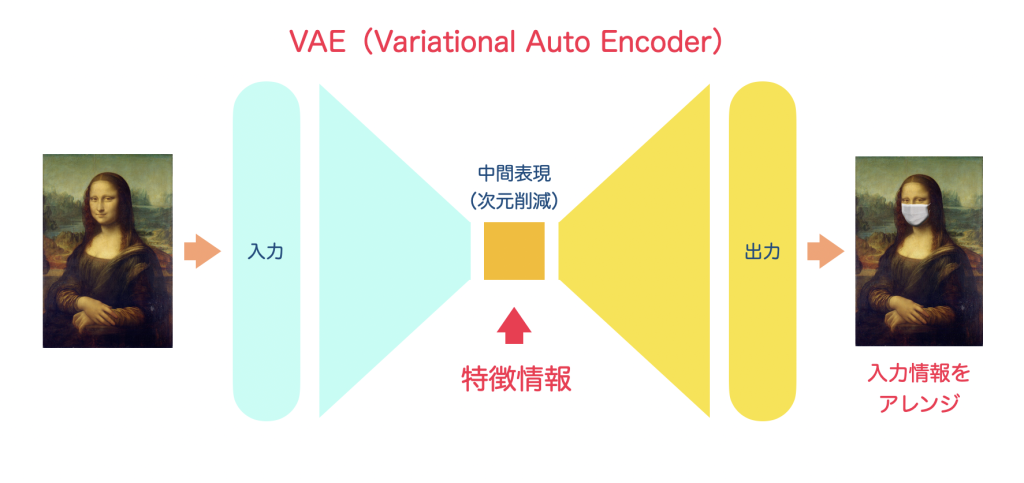
また、中間表現にアレンジ情報を加えて、入力データにアレンジを加えた出力データを生成するVAE(Variational Auto Encoder)もあります。
(あくまでイメージの図面です)
音楽トークンの生成に使われるVQ-VAEは、このVAEの派生で、中間層の情報を量子化し、一定数のコードに分類します。これがコードブックとも言われます。
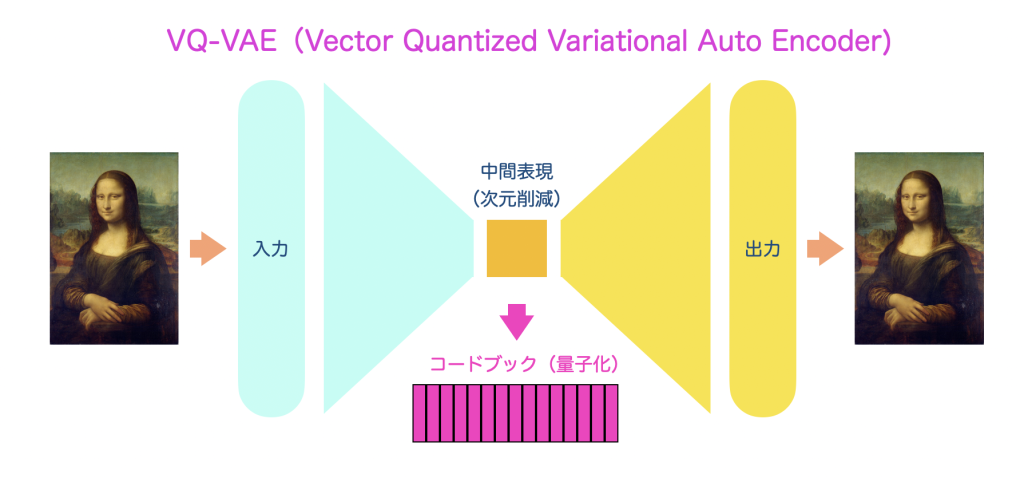
このコードブックが音楽トークンの辞書のようなものになります。だいたい512種類ぐらいのコードに分類されます。VQ-VAEのすごいところは、音の特徴を抽出して、「近しい音が同じコードになる」ようにコードの定義も同時に学習していきます。
ではなぜこのような離散化されたコードを使うのかですが、連続値のベクトル状態ですと学習も生成も不安定になるからです。連続値だとちょっとズレただけで「全然違う意味」とみなされる可能性もあり難しいのです。離散トークンにすると、「これは激しい音だな」「これは静かな音だな」とカテゴリ分けもできて安定し、音楽の「だいたい感」(ジャンル、スタイル、流れ)をうまく学習できるようになります。音楽の設計図としては、細部の情報よりも全体のまとまり感の方が大切なため、離散化したトークンの方が全体のまとまり感を統制しやすく、このような音楽トークンとなるコードブックが用いられています。
ここで作られたコードブックが音楽トークンとして、次のTransformerやその後のDiffusionで使われていきます。いわばここはまだ下準備です。
Transformer
AIのニュース等でもTransformerやGPTなんていう専門用語が飛び交うようになりました。ここでは少しだけTransformerのイメージをお話します。
Transformerは、DeepLearning(深層学習)のアーキテクチャのひとつで、Googleが2017年に発表した論文 “Attention Is All You Need” で機械翻訳の性能を飛躍的に向上させ、その後、機械翻訳だけでなく、画像処理や音楽生成などさまざまなタスクでも使われていくようになったものです。
言語機械翻訳を例にしたイメージ図です。「”I like music”という英語を日本語に翻訳せよ」というタスクを例にします。
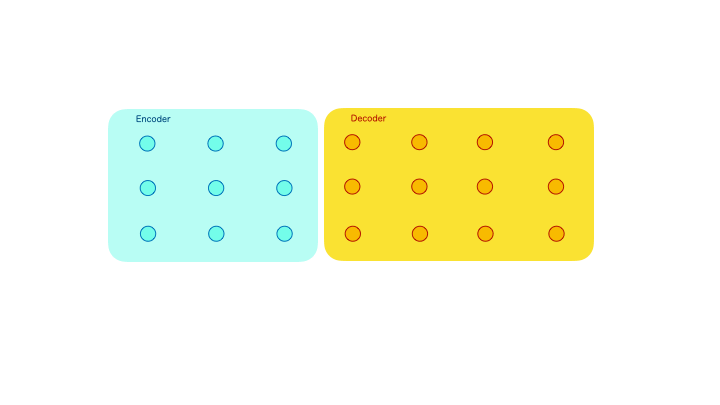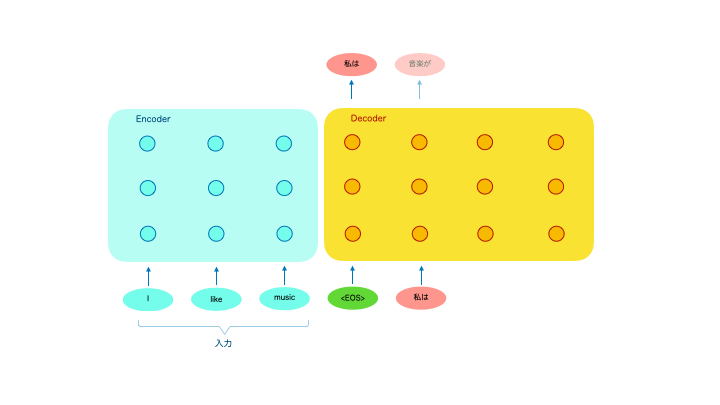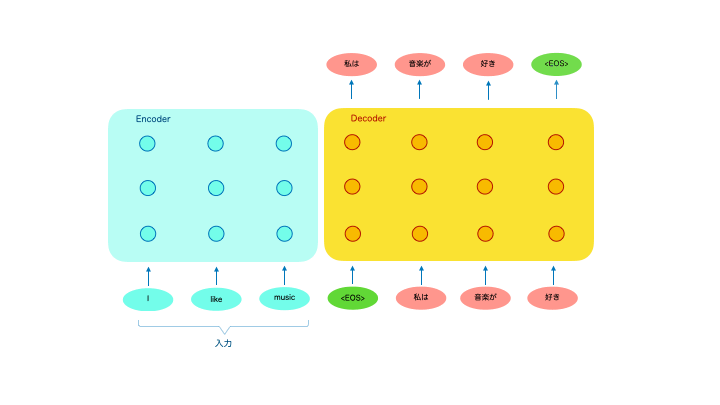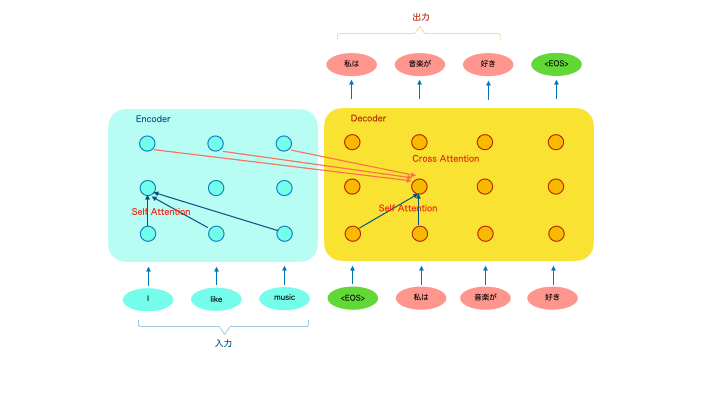
Transformerの基本形にはエンコーダと言われる左側部分とデコーダと言われる右側部分があります。エンコーダに”I like music”を入力すると、デコーダからその翻訳結果の「私は音楽が好き」がでてきます。
基本的には文章を単語単位に分割して入力し、翻訳結果も単語単位で出力されてきます。デコーダは1単語ごとに出力され、出力された単語は次の出力の計算に使われます。
つまり翻訳結果の単語生成には、入力された原文の全単語と、それまでに出力した翻訳結果の単語が複雑に計算されて、次に出す最適な単語を計算しているというイメージです。
内部の計算にはSelf-AttentionやCross-Attentionなどのアテンションベースの計算が行われております。もともとこのような時系列に左から右に生成していくモデルには、RNNやLSTMなどのリカレントニューラルネットワークが用いられており、アテンションは付加的に使われていたのですが、2017年の”Attention is All You Need”の論文でアテンションが全てになりました。
音楽も時系列な信号のため、左から右に生成していく点は同様です。なのでこれを音楽生成に応用した構成がこちらになります。
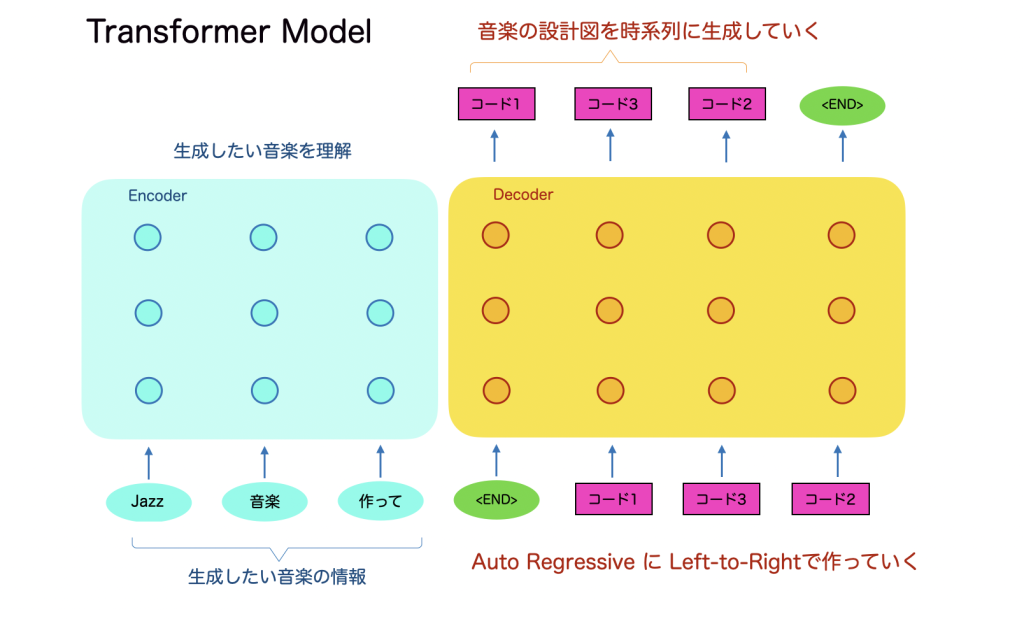
エンコーダにはどんな音楽を作るかの情報が入ります。例として「Jazz音楽作って」という指示を入れると、ここは機械翻訳と同様にエンコーダがその文意を理解します。次にデコーダはその文意に基づいて、音楽のトークン列を生成していきます。ここに先ほどのVQ-VAEで定義したコードブックのコードがでてきます。つまり音楽トークンの配列が生成されます。音楽とトークンのマッピングはVQ-VAEでできてますので、音楽からトークン配列を作ることもできますので、学習が可能になります。
こうしてできたTransformerで、音楽を生成する指示文から音楽の設計図である音楽トークン配列ができあがります。この時点で、音楽のおおまかな概略はもうできています。
Diffusion
Diffusionモデルは、ノイズから逆拡散によって意味のある情報を生成していくモデルで、Stable Diffusion等の画層生成でも用いられています。これで、音楽の波形を作っていくという最後の仕上げをしていきます。
まず、Diffusionモデルの概要ですが、画像生成で説明しますと、オリジナルの画像をステップごとに少しずつノイズを加えていき、ただのノイズになるところまで作っていきます。このステップを逆にして、ノイズからひとつ前のステップの画像を生成するモデルを学習していきます。推論時は、1回で画像を生成するのではなく、何回もステップを踏みながら少しずつノイズを逆拡散していき画像生成していくイメージです。
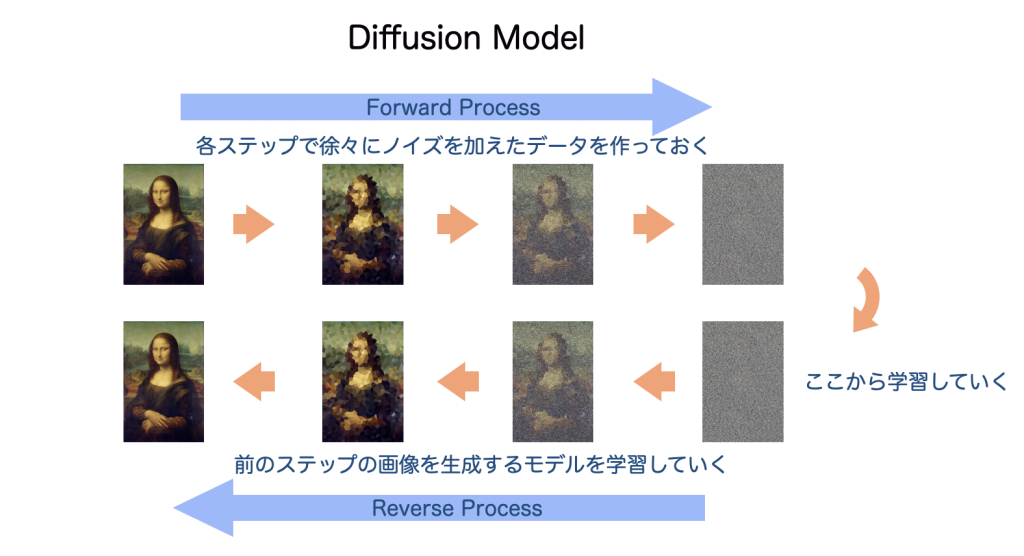
(あくまでイメージ図です)
これを音楽の波形生成に使います。Transformerで音楽トークン配列はできました。またトークンと音楽のマッピングはVQ-VAEでできています。つまり音楽でいう白色ノイズに対して、トークンを情報としそれにマッピングした音楽の波形を何ステップもかけて作っていくという学習が可能です。
このようにしてできたDiffusionモデルを使って、Transformerから出力された音楽トークン配列から各トークンごとに波形を生成していきます。
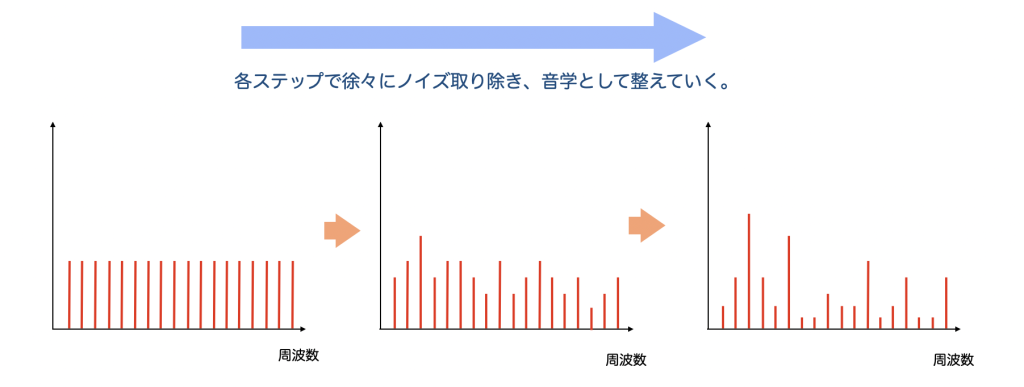
最初は全周波数帯にエネルギーのあるホワイトノイズから始まり、徐々に周波数スペクトルが音楽らしく整っていきます。ノイズだけの海に、ときどき、温かなピアノが浮かんできたり、ドラムのようなリズムが現れてきたりします。音楽は流れが大事なので該当トークンだけでなく前後のトークンや波形も参照して生成していきます。
これにより新たな生成音楽が仕上がります。
まとめ
以上、音楽生成AIのざっくりとした仕組みの説明でした。
ここまでできたら、もう一歩先を想像してみましょう。DNA配列を書き換える遺伝子組み換え技術と同じように、音楽も、音楽トークン列を分解し、別の音楽の列と繋げて、まったく新しいハイブリッド音楽を作ることができるかもしれません。
そしてそれは、これまでの音楽スタイルにとらわれない、未知のアートを生み出す可能性があるかもしれません。
少なくとも作曲のインスピレーションにはなるかと思います。